golang:GO堆栈和指针
原文链接
https://www.ardanlabs.com/blog/2017/05/language-mechanics-on-stacks-and-pointers.html
前言
这是四部分系列中的第一篇文章,它们将提供对Go中指针,堆栈,堆,转义分析和值/指针语义背后的机制和设计的理解。 这篇文章的重点是堆栈和指针。
四部分系列索引:
介绍
我不打算否认这个观点–指针很难理解。 如果使用不当,指针可能会产生令人讨厌的错误甚至性能问题。 在编写并发或多线程软件时尤其如此。 难怪这么多语言试图隐藏指针远离程序员。 但是,如果您在Go中编写软件,则无法避免它们。 如果没有对指针的强烈理解,您将很难编写干净,简单和高效的代码。
函数Frame边界
函数在Frame边界的范围内执行,为每个相应的函数提供单独的存储空间。 每个Frame允许功能在其自己的上下文中操作,并且还提供流控制。 函数可以通过Frame指针直接访问其Frame内的内存,但访问其Frame外的内存需要间接访问。 函数如果要访问其Frame外部的内存,该内存必须与该函数共享。 需要首先理解和学习由这些Frame边界建立的机制和限制。
调用函数时,会在两函数的Frame之间发生转换。 代码从调用函数的Frame转换到被调用函数的Frame。 当函数调用需要进行参数传递时,在Go中两个Frame之间这种传递数据是“按值”完成的。
“按值”传递数据的好处是可读性。 您在函数调用中看到的值是在另一侧复制和接收的值。 这就是我将“按值传递”与所见即所得联系起来的原因,因为你所看到的就是你所得到的。 所有这些都允许您编写不会隐藏两个函数之间转换成本的代码。 这有助于维持一个良好的心理模型,表明每个函数调用在转换发生时将如何影响程序。
看看这个执行函数调用的小程序“按值”传递Integer数据:
01 package main
02
03 func main() {
04
05 // Declare variable of type int with a value of 10.
06 count := 10
07
08 // Display the "value of" and "address of" count.
09 println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
10
11 // Pass the "value of" the count.
12 increment(count)
13
14 println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
15 }
16
17 //go:noinline
18 func increment(inc int) {
19
20 // Increment the "value of" inc.
21 inc++
22 println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
23 }
当Go程序启动时,运行时会创建主goroutine以开始执行所有初始化代码,包括main函数内的代码。 从版本Go1.8开始,每个goroutine都有一个初始的2,048字节的连续内存块,形成了它的堆栈空间。 多年来,这个初始堆栈大小发生了变化,将来可能会再次发生变化。
堆栈很重要,因为它为每个单独函数的提供了物理内存空间和Frame边界。 当主goroutine执行以上代码中的main函数时,goroutine的堆栈将如下所示(仅从high level角度来看):

您可以在上图中看到,堆栈的一部分已被给配给main函数使用。 此部分称为stack frame,它表示了main函数在堆栈中的边界。 当函数被调用时,该stack frame作为代码运行的一部分被建立。为调用函数时执行的代码的一部分。 您还可以看到count变量被分配在main函数frame内的地址0x10429fa4处。
上图还清楚地说明了另一个有趣的观点。Active Frame下面的所有堆栈内存空间都是无效的,但是Active Frame及以上的堆栈内存空间是有效的。 我需要清楚堆栈的有效和无效部分之间的边界。
地址
变量用于为特定内存位置分配名称,以便更好地编写代码,并帮助您推断正在使用的数据。 如果你有一个变量,那么你在内存中有一个值,如果你在内存中有一个值,那么它必须有一个地址。 在第09行,main函数调用内置函数println来显示计数变量的“值”和“地址”。
09 println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
使用&运算符来获取变量位置的地址并不新颖,其他语言也使用此运算符。 如果你在32位CPU上运行这段代码,那么第09行的输出应该类似于下面的输出:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
函数调用
接下来在第12行,main函数调用increment函数。
12 increment(count)
进行函数调用意味着goroutine需要在堆栈上构建新的内存部分。 然而,事情有点复杂。 为了成功进行此函数调用,期望数据在frame边界上传递并在转换期间放入新frame中。 具体而言,期望在调用期间复制并传递一个integer值。 您可以通过查看第18行的increment函数声明来查看此要求。
18 func increment(inc int) {
如果你在第12行看到函数调用再次递增,你可以看到代码正按值传递count变量。 该值将被复制,传递并放入increment函数的新frame中。 请记住,increment函数只能在其自己的帧中直接读取和写入内存,因此它需要一个被传递的count值的副本–变量inc,来接收,存储和访问自己。
就在increment函数内部的代码开始执行之前,goroutine的堆栈(仅从high level角度来看)将如下所示:

您可以看到堆栈现在有两个frame,一个用于main函数,另一个用于increment函数。 在increment函数frame内,您会看到变量inc,它包含在函数调用期间复制并传递的值10。变量inc的地址是0x10429f98,改地址值位于较低的内存地址,因为堆栈中frame是往下增长的,这只是一个实现细节,并不意味着什么。 重要的是,goroutine从main函数frame中获取count的值,并将该值copy给increment函数frame中的副本inc变量。 函数increment内的其余代码递增并显示inc变量的“value”和“address”。
21 inc++
22 println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
第22行的输出应该如下所示:
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
这是执行以上代码行后堆栈的样子:
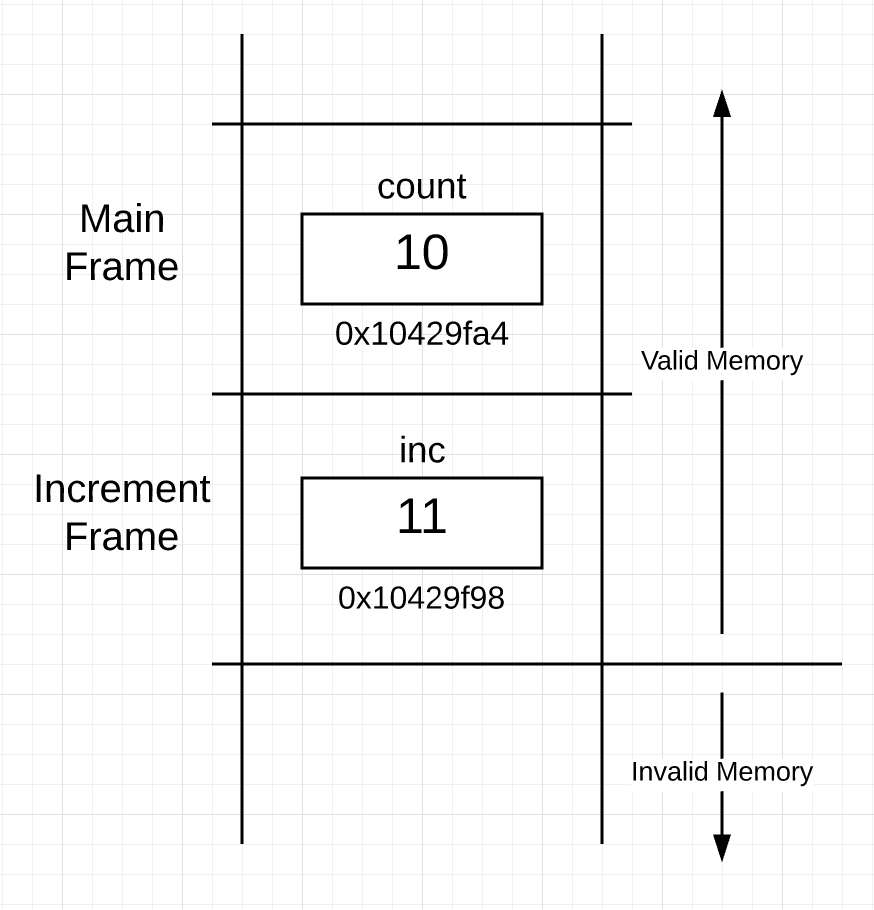
在执行第21行和第22行之后,函数increment 返回到main函数。 然后main函数再次在第14行显示“value of”和“address of”本地变量count。
14 println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")
程序的完整输出应如下所示:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
在main函数的frame 中变量count的值在增量调用之前和之后是相同的。
函数返回
当函数返回到调用函数时,堆栈上的内存实际发生了什么? 简短的回答是什么。 这是函数increment 返回后堆栈的样子:
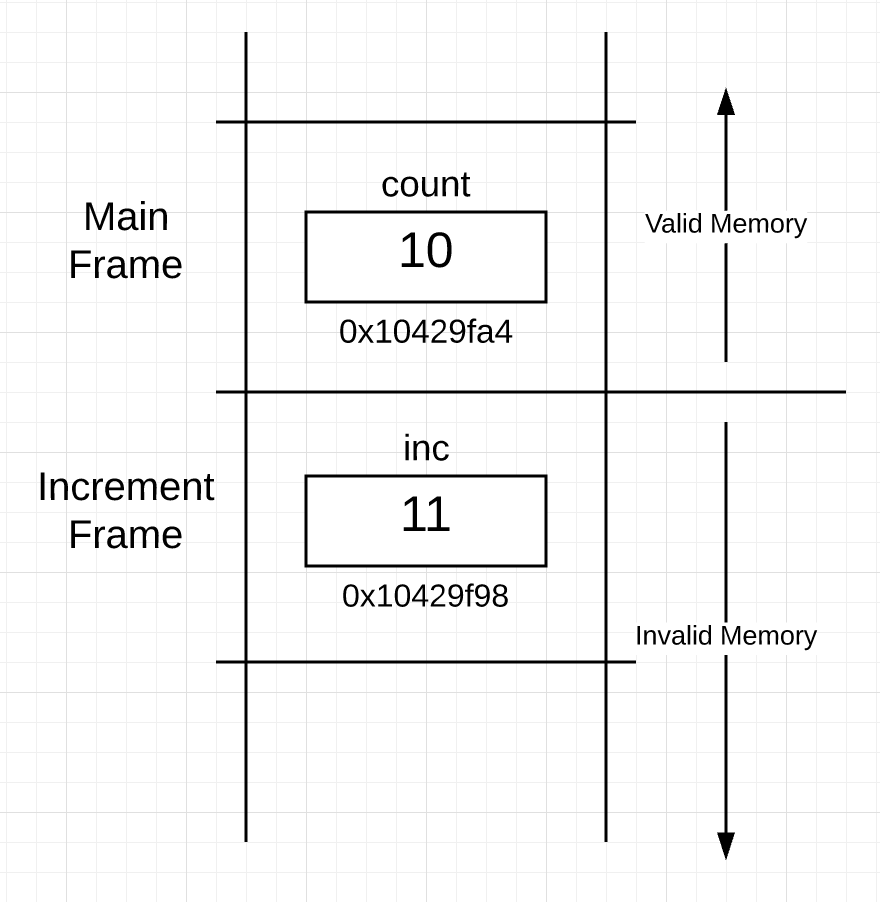
堆栈空间看起来与图3完全相同,只是与increment函数关联的帧现在被认为是无效内存。 这是因为main函数的frame现在是active frame。 为函数increment分配的frame构成的内存保持不变。 清理已返回函数frame的内存是浪费时间和不必要的,因为您不知道是否再次需要该内存。 所以函数返回时只需要将该内存区域保持原样。 在每个函数调用期间,当新的函数被调用时,被调函数新的frame被重新分配,这时该frame的堆栈存储空间被擦除干净。 这是通过初始化放置在函数frame中的任何值来完成的。 因为所有值都被初始化为至少它们的“零值”,所以堆栈在每次函数调用时都能正确清理它们。
共享变量
如果函数increment需要直接对main中frame中的count变量进行操作怎么办? 这时指针就派上用场了。指针可以用来与函数共享一个值,即使该值不存在于函数自己的frame内,该函数可以读取和修改该值。
如果你不需要共享存储空间,你不需要使用指针。 在学习指针时,使用清晰的词汇表而不是运算符或语法来思考是很重要的。 所以请记住,指针用于共享,并在读取代码时使用“共享”一词来替换&运算符。
指针类型
无论是由语言本身声明的类型(内置类型),还是你自己定义的类型,你都可以直接获得该类型的指针类型来进行内存共享。 已经存在一个名为int的内置类型,因此有一个名为* int的指针类型。 如果声明一个名为User的类型,则可以获得一个名为* User的指针类型。
所有指针类型都具有相同的两个特征。 首先,他们从字符*开始。 其次,它们都具有相同的内存大小和表示形式,即表示地址的4或8个字节。 在32位体系结构(如go playground)上,指针需要4个字节的内存,而在64位体系结构(如我的机器)上,它们需要8个字节的内存。
在规范中,指针类型被认为是literals类型,这意味着它们是由现有类型组成的unnamed类型
间接内存寻址
看看下面这个函数调用的例子,函数参数通过“按值”传递方式传递一个地址。 这将使increment函数可以从main函数frame中共享到count变量:
01 package main
02
03 func main() {
04
05 // Declare variable of type int with a value of 10.
06 count := 10
07
08 // Display the "value of" and "address of" count.
09 println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
10
11 // Pass the "address of" count.
12 increment(&count)
13
14 println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
15 }
16
17 //go:noinline
18 func increment(inc *int) {
19
20 // Increment the "value of" count that the "pointer points to". (dereferencing)
21 *inc++
22 println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]\tValue Points To[", *inc, "]")
23 }
与之前例子相比,该程序进行了三处有意思的修改。 如下是第12行的第一个更改:
12 increment(&count)
在第12行,代码不是复制并传递变量count的“值”而是传递变量count的“地址”。 你可以理解为,操作符&正在将变量count共享给函数increment。 操作符&传达的意思就是“共享”。 需要说明的是这仍然是“按值传递”,唯一的区别是传递的值是地址而不是integer。 地址也是值,该值在函数调用过程中,通过复制并传递。 由于正在复制和传递的值是一个地址,因此在函数地址frame内需要一个变量来接收和存储这个基于整数的地址。 这是整数指针变量的声明出现在第18行的地方。
18 func increment(inc *int) {
如果您传递的是User值的地址,那么该变量需要声明为* User。 即使所有指针变量都存储地址值,它们也不能传递任何地址,只能传递与指针类型相关的地址。 这是关键,共享值的原因是因为接收函数需要对该值执行读取或写入。 只有给定一个值的类型信息才能,对该值进行读取和写入。 编译器会对被“共享”的值类型与接受函数的指针类型进行检查。只有类型匹配,编译器才允许共享。
这是调用函数increment后堆栈的样子:
{kind=link}
您可以在上图5中看到,当使用地址作为值执行“按值传递”时堆栈的样子。 函数increment 堆栈frame内的指针变量现在指向count变量,该变量位于main函数的frame内。 现在使用指针变量,该函数可以对位于main函数frame内的count变量执行间接读取修改写入操作。
21 *inc++
现在,字符充当操作符并应用于指针变量。 使用作为运算符意味着“指针指向的值”。 指针变量允许在使用它的函数框架之外进行间接内存访问。 有时,这种间接读取或写入称为对指针解引用。 函数increment仍然必须在其框架内具有指针变量,它可以直接读取以执行间接访问。 在执行完第21行后,你可以看到堆栈的样子如下图图6:
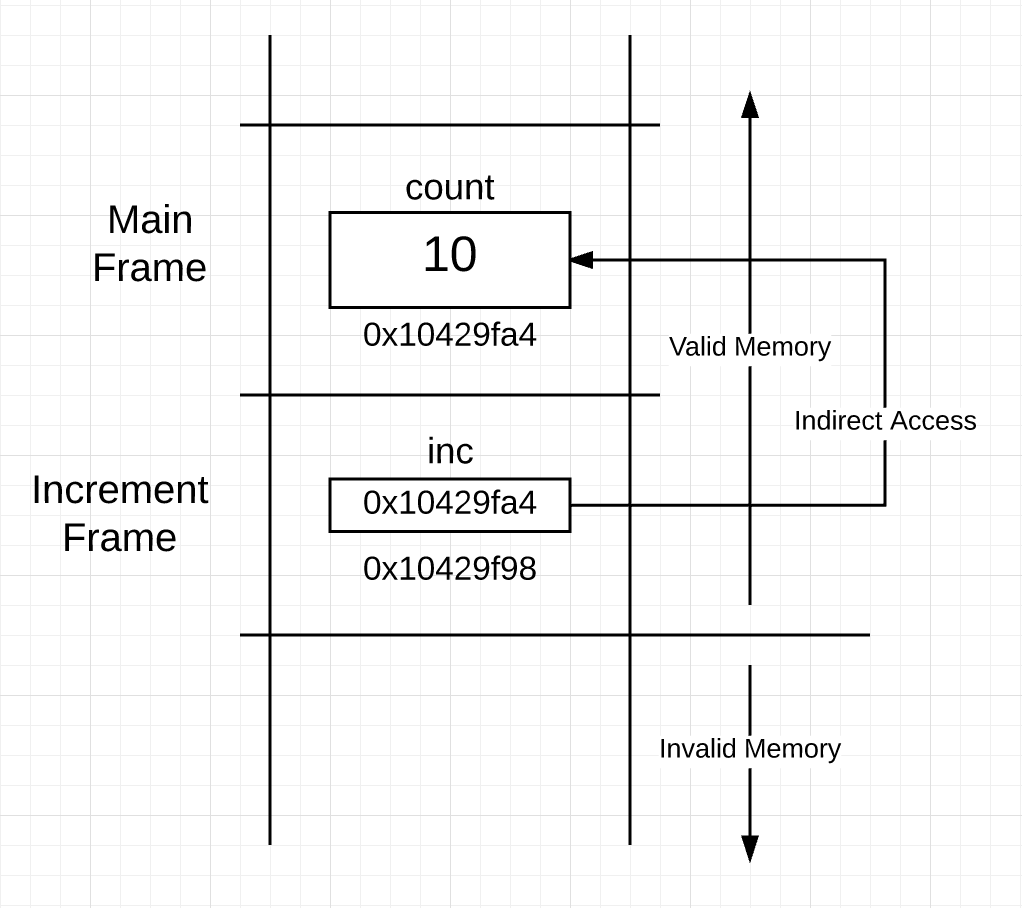{kind=link}
该程序的最终输出如下:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 0x10429fa4 ] Addr Of[ 0x10429f98 ] Value Points To[ 11 ]
count: Value Of[ 11 ] Addr Of[ 0x10429fa4 ]
您可以看到inc指针变量的“值”与count变量的“地址”相同。 这将建立共享关系,允许间接访问frame外部的内存。 一旦函数increment通过指针执行写入,在返回时main函数会看到值被更改。
指针变量也是变量
指针变量并不特殊,因为它们是与任何其他变量一样的变量。 他们有一个内存分配,他们持有一个值。 只是碰巧所有指针变量,无论它们指向的值的类型如何,总是具有相同的大小和表示。 可能令人困惑的是*字符即在代码中充当操作符,也用于声明指针类型。 如果您可以将类型声明与指针操作区分开来,这可以帮助减轻一些混淆。
结论
这篇文章描述了指针背后的目的,以及堆栈和指针机制在Go中的工作原理。这是理解编写一致且可读代码所需的机制,设计理念和指南的第一步。
总之,在这篇文章中你学到了:
- 函数在堆栈Frame边界的范围内执行,为每个相应的函数提供单独的存储空间。
- 调用函数时,两函数frame之间会发生转换。
- “按值”传递数据的好处是代码可读性强。
- 堆栈很重要,因为它为每个函数frame边界提供了单独的物理内存空间。
- Active frame下方的所有堆栈内存均无效,但Active frame及以上内存有效。
- 进行函数调用意味着goroutine需要在堆栈上构建新的frame内存部分。
- 在每个函数调用期间,当frame被分配时,该frame的堆栈存储器被擦除干净。
- 指针用于一个目的,与函数共享一个值,因此函数可以读取和写入该值,即使该值不存在于其自己的框架内。
- 对于您或语言本身声明的每种类型,您可以直接使用该类型对应的指针类型来进行数据共享。
- 指针变量允许在使用它的函数frame之外进行间接内存访问。
- 指针变量并不特殊,因为它们是与任何其他变量一样的变量。他们有一个内存分配,他们持有一个值。